
中国 R 会演讲之《访问总量 1700万+ 的疫情数据可视化应用的开发故事》
首先欢迎大家听我这次基本没有什么硬核干货的分享报告。
这次报告没什么高大上很难懂的东西,主要是分享我自己的一个 {shiny} 应用开发故事和从中得到的一些经验,希望能帮助到 {shiny} 应用开发的新手在更短的时间内做出一个美观和实用性兼备的应用。
学艺不精,还请大家多多包涵。
大家也都知道,今年年初以武汉为中心爆发了新冠疫情这个黑天鹅事件。
我本身就是在武汉度过了我的大学时光,在武汉也留下了很多回忆,自然而然也就十分牵挂武汉的疫情情况,每天看着各种报道,很揪心但又由于自己刚毕业人在海外,时间和金钱方面也都没什么富余的地方,想帮忙也一时半会想不到什么好办法。虽然现在自己也已经转行了,但本科的时候也是和病毒组学打过交道的,所以我那个时候常常在想,能不能以自己的方式,在抗疫方面能够做点什么。

先将时间轴扳回到今年1月,丁香园在疫情最初期的时候就迅速上线了疫情实时动态的移动页面。随后到了1月下旬左右各大平台都接连推出自己的疫情动态相关页面。
这些页面依我看来主要有图上的几个特点。
自己在工作以后,也没什么机会再去接触 R 语言了,但又不想忘掉自己懂得的技能,那何不借此次机会做点什么,同时复习一下 {shiny} 开发吧。而且就 {shiny} 的特性而言,我完全能够选择和大厂不同的路线,去做自己的疫情应用,让它能够拥有一些值得被用户选择的理由。

大厂选择注重移动平台,那我就关注传统PC平台的用户体验;大厂考虑普遍大众,那么我可以更倾向于给具有研究素养的用户快速提供他们想了解的信息。 而且个人的精力有限,不可能做到实时推送信息,那么我就只关注数据展示就行了,毕竟步子迈大了容易 hold 不住。 这样一来多多少少做到了差异化,找准了自己的定位,才有保持稳定长期运营的可能性,要不然依个人经验很大概率最后会沦为一个个人娱乐或练习性质的项目。而且不管是代码还是数据统统开源,即使在疫情结束后,肯定也不缺乏需要数据进行相关科研的研究者。 所以即使是零新增后,这个项目也还有它存在的意义。

由于在研究生期间也通过开发 RNASeq 差异基因分析 {shiny} 工具 TCC-GUI 积累了一定经验,
所以对关于如何创建一个有模有样的 {shiny} 应用方面也大概有个了解,如果想实现某种功能的时候,应该选择哪些R包来达到目的。很快就凭借着还记着的一点相关知识,和上次一样主题框架选择 {shinydashboardPlus} ,数据变换用了 {data.table} ,并且由于是网页应用而不是写论文,
可视化方面就没有选择传统的 {ggplot2} 而是注重交互的 {plotly},很多方面也没有细想,项目就这么在1月30日的时候开始了。
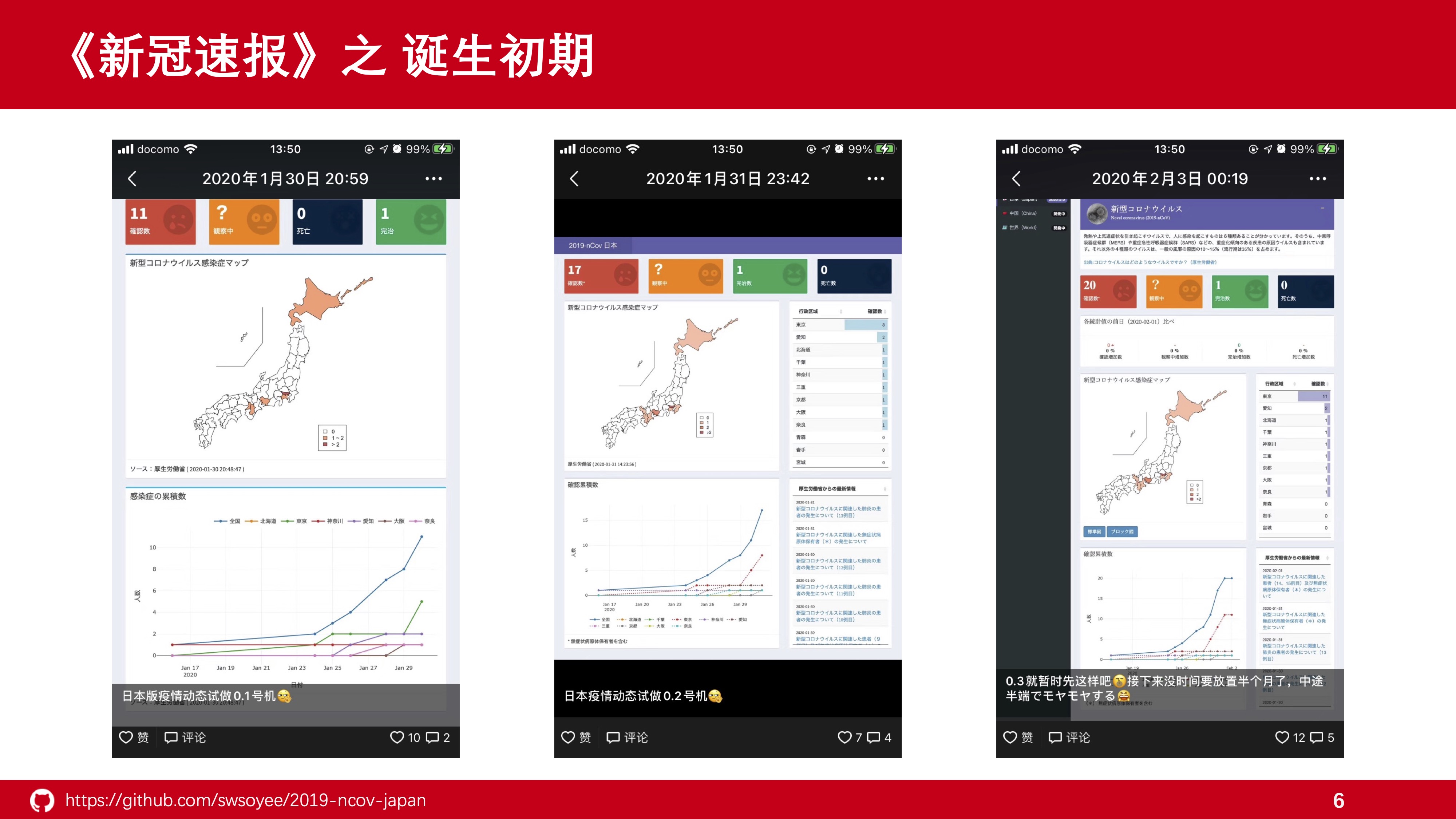
在刚开始的时候,日本确诊人数非常少,整体数据情况也不算复杂,于是也模仿了国内疫情动态页面分为三层,顶层为关键数值,中间层为疫情地图,底层为随时间的确诊情况图。
初期的时候,疫情地图是用基础R绘制的静态图像,用 {plotly} 绘制的各省份确诊情况图也非常粗糙,让人难以迅速掌握具体数值,所以又在右侧再次添加了各省份的总确诊人数表和信息来源表。
从画面上我们不难看出,页面上存在着大量空白区域,整个画面其实也没多大信息量。充其量也就是一个总人数和各省确诊人数情况而已。
不过也由于还是没有任何计划性的个人开发,所以就边试错,边学习,边改进了。
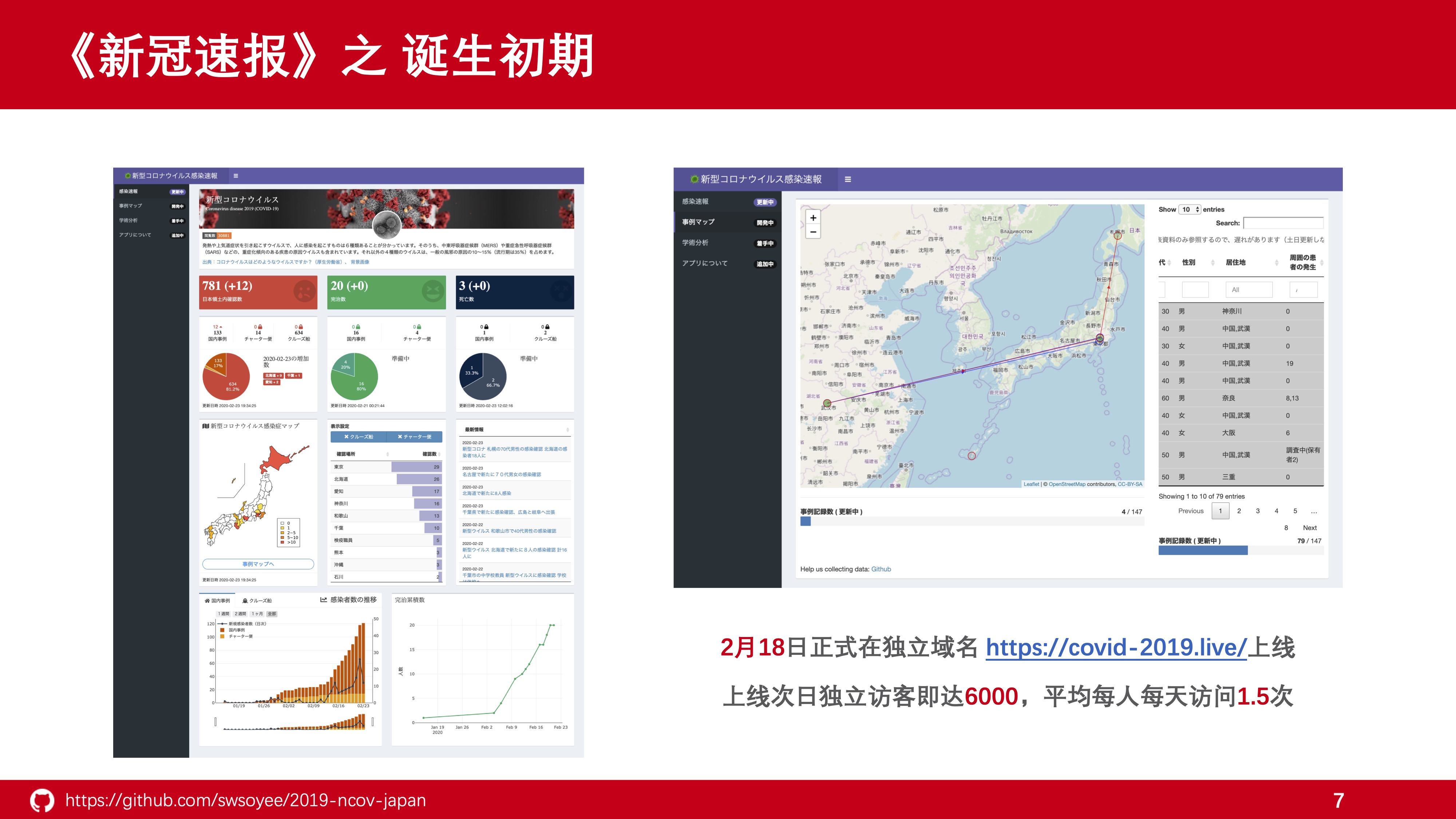
之后由于一些原因开发工作也停滞了半个月,2月中旬后又接着继续进行迭代。
随后整体布局一直在调整,直到2月18日左右在前辈的帮助下,摆脱免费的 shinyapps.io 的限制,
使用了独立域名和服务器让《新冠速报》正式上线。在完全是口口相传的方式下,上线首周就收获到了不少流量。
但是在目前来看,这个仪表盘应用还是不那么令人满意,而且在运营的过程中也发现了不少问题。
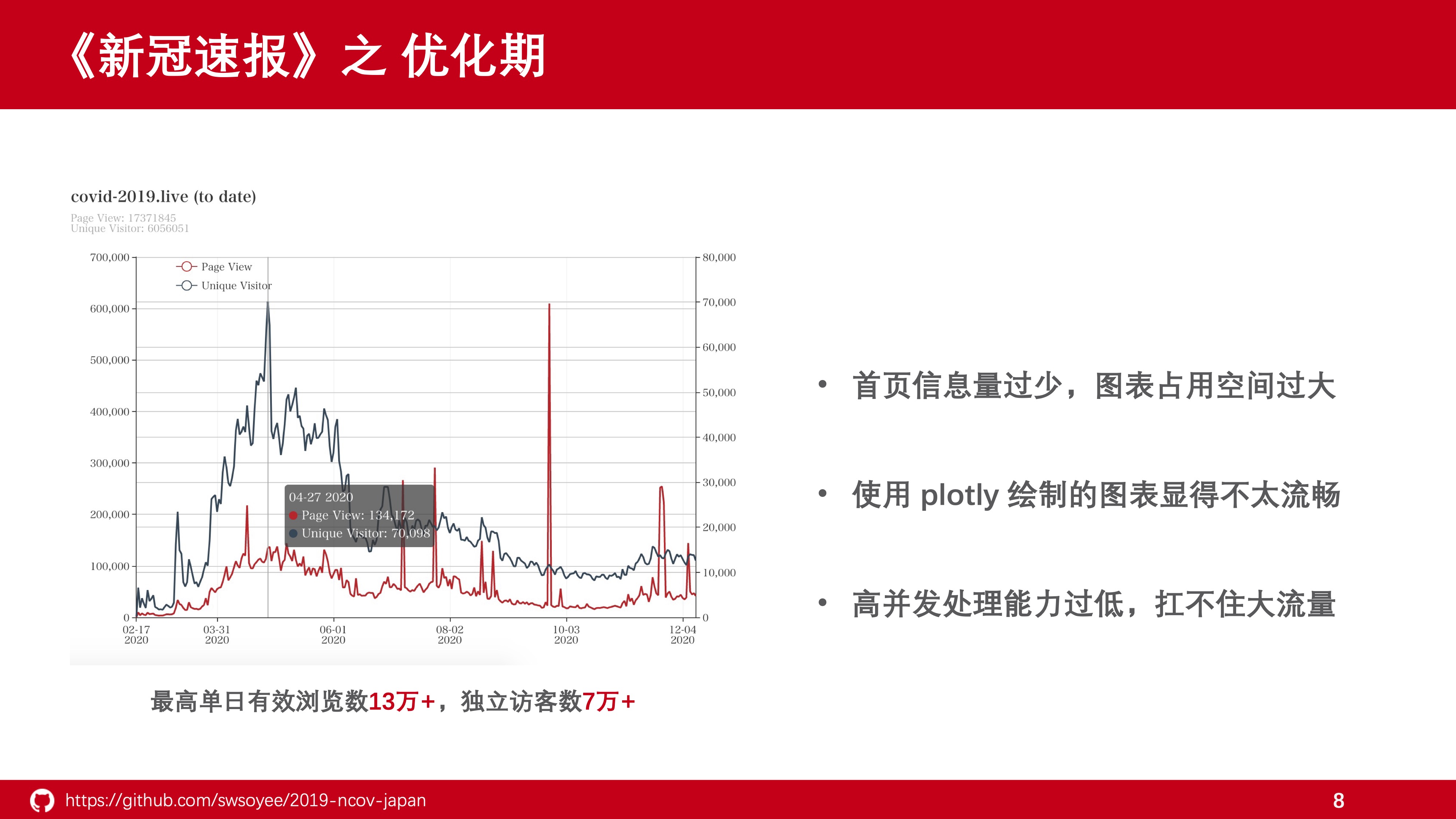
在这里我主要挑图上的 3 点来做详细说明。 并且简要介绍一下我是如何对这 3 个问题进行优化的。
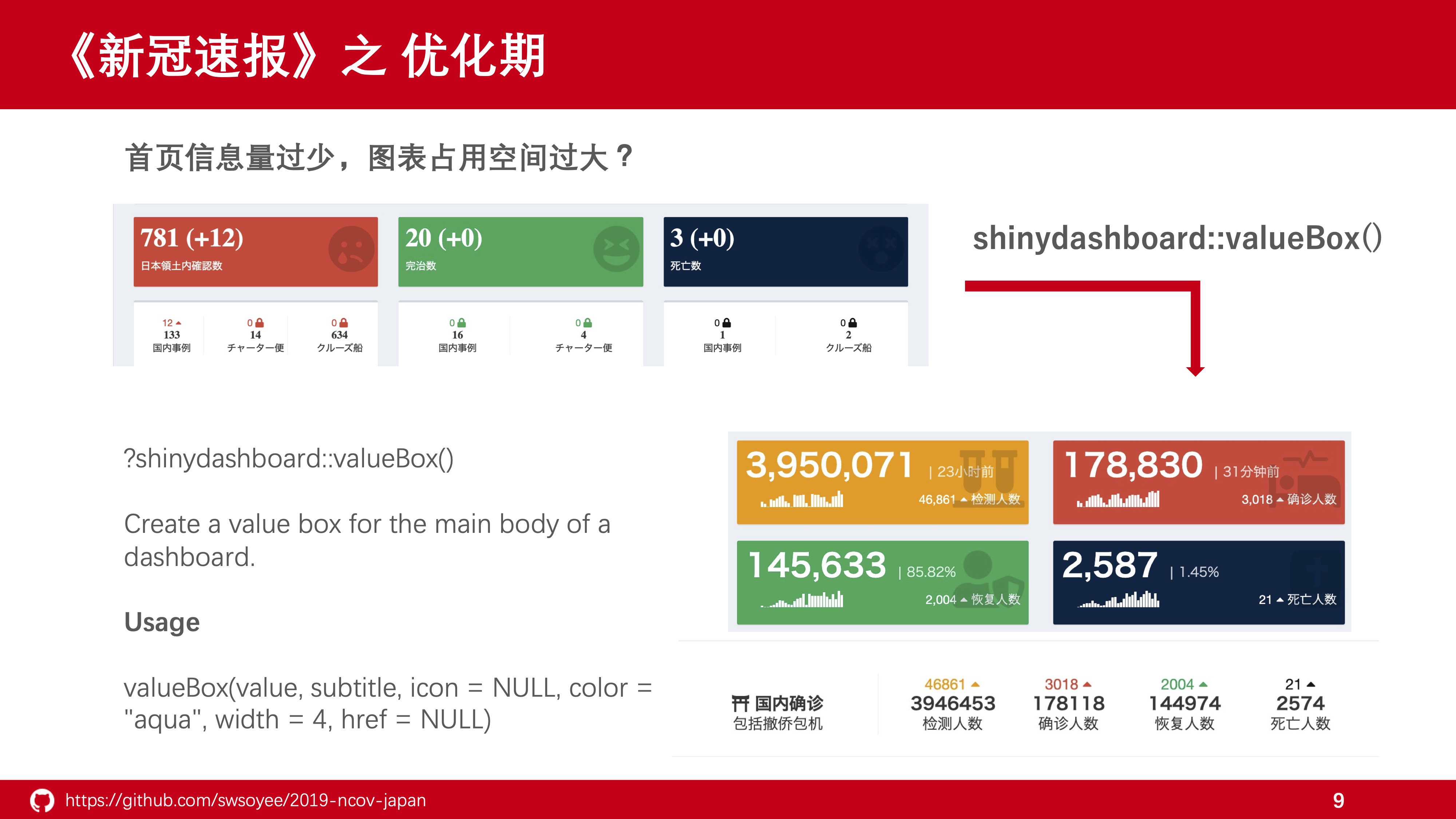
以 {shinydashboard} 中的数值组件 valueBox 举例说明,当你查看函数帮助的时候,只能看到有数值、说明、图标、颜色、宽度和链接等选项。对于初学者来说,根据帮助所提供的信息,只能完成左上角的效果。
但其实如果稍微深入了解一下这个函数的本质,估计就能发现一个不一样的世界了。

我们直接在R控制台中查看 valueBox 函数的输出结果,其实本质上不过生成了一些带有 BootStrap 样式名称的标签罢了。
当我们搞明白这一点后,就完全可以直接在参数里自己添加额外的元素,从而完成对组件的定制。
其实在 {shiny} 的官方文档中也有相关的说明,但我相信有不少刚开始接触 {shiny} 开发的伙伴们就和我一样,基本就是看到一个好看的主题框架直接就拿过来用了,直到捣鼓到一定地步,觉得不够用了才会想去看看背后的实现方法。

出于相同的原因,我们同样可以对表格部分进行拓展,至于表格展示 {DT} 包的本质身我也不能算完全理解透彻,所以我这个外行也就不在此班门弄斧了。
主要想指出的一点就是,当理解了 {shiny} 前端几乎所有元素都是基础 html 标签和一些 JavaScript 构成的这一点之后,你就可以不受文档本身中说明到的东西所限,而可以发挥你的想象,做出任何你想要的效果来。
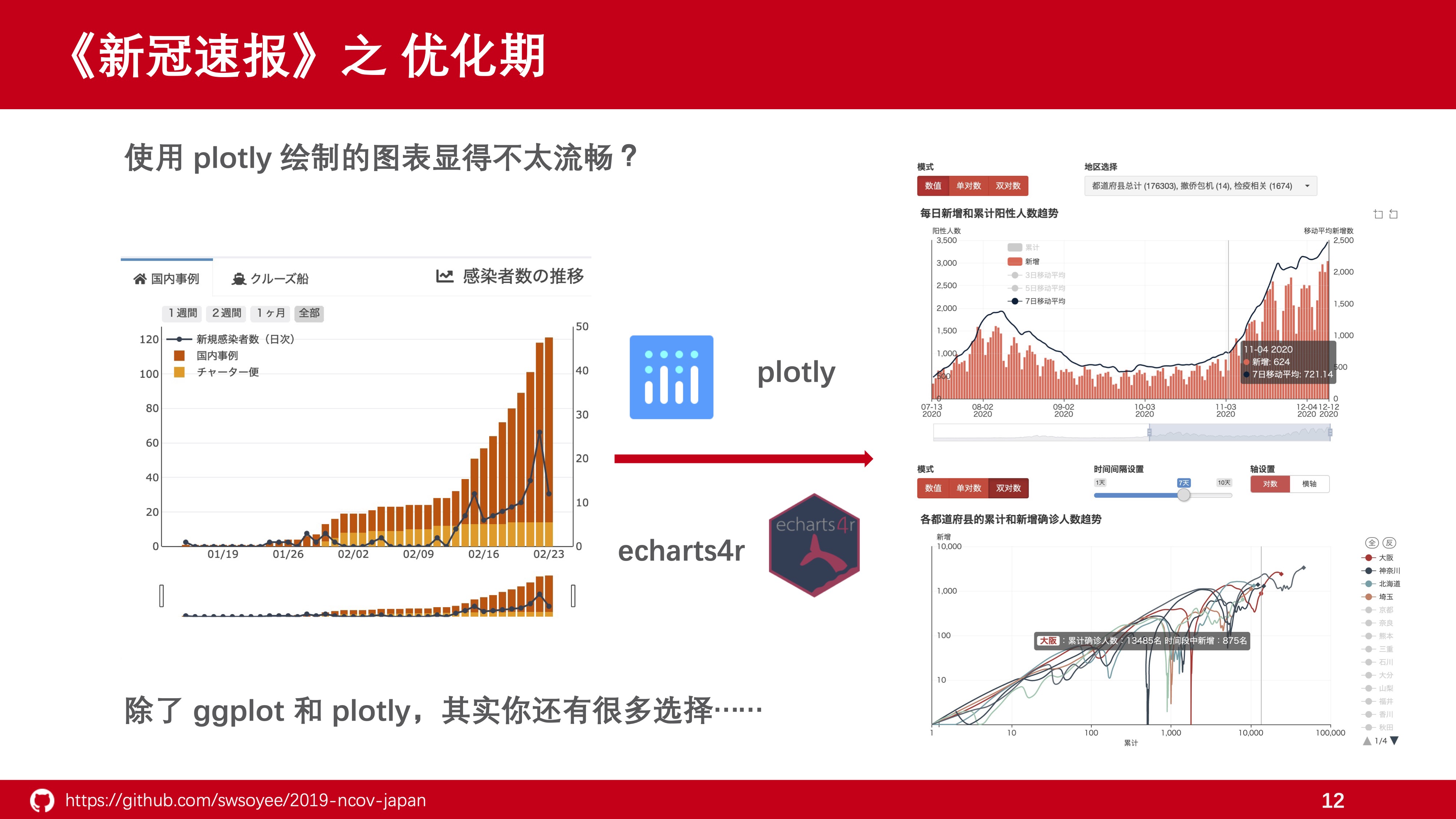
网页应用的流畅程度特别影响用户对该页面的印象,如果一些动态特效不太流畅的话,会扣不少印象分。
R语言其很大的一个优势就是特别容易绘图,我相信没有哪个用户会不知道 {ggplot2},而了解过交互式可视化的话,肯定也知道 {plolty}。
但在构建 {shiny} 应用的时候,其实我们还有很多选择。
在经过了一番调研后,我选择了用 {echarts4r} 这个包重新作为我的绘图依赖,完全放弃 {plotly}。{echarts4r} 其本质就是把百度团队用 JavaScript 实现的可视化开源库 Echarts 做了一个 R 语言接口,使R用户能够用上 Echarts。
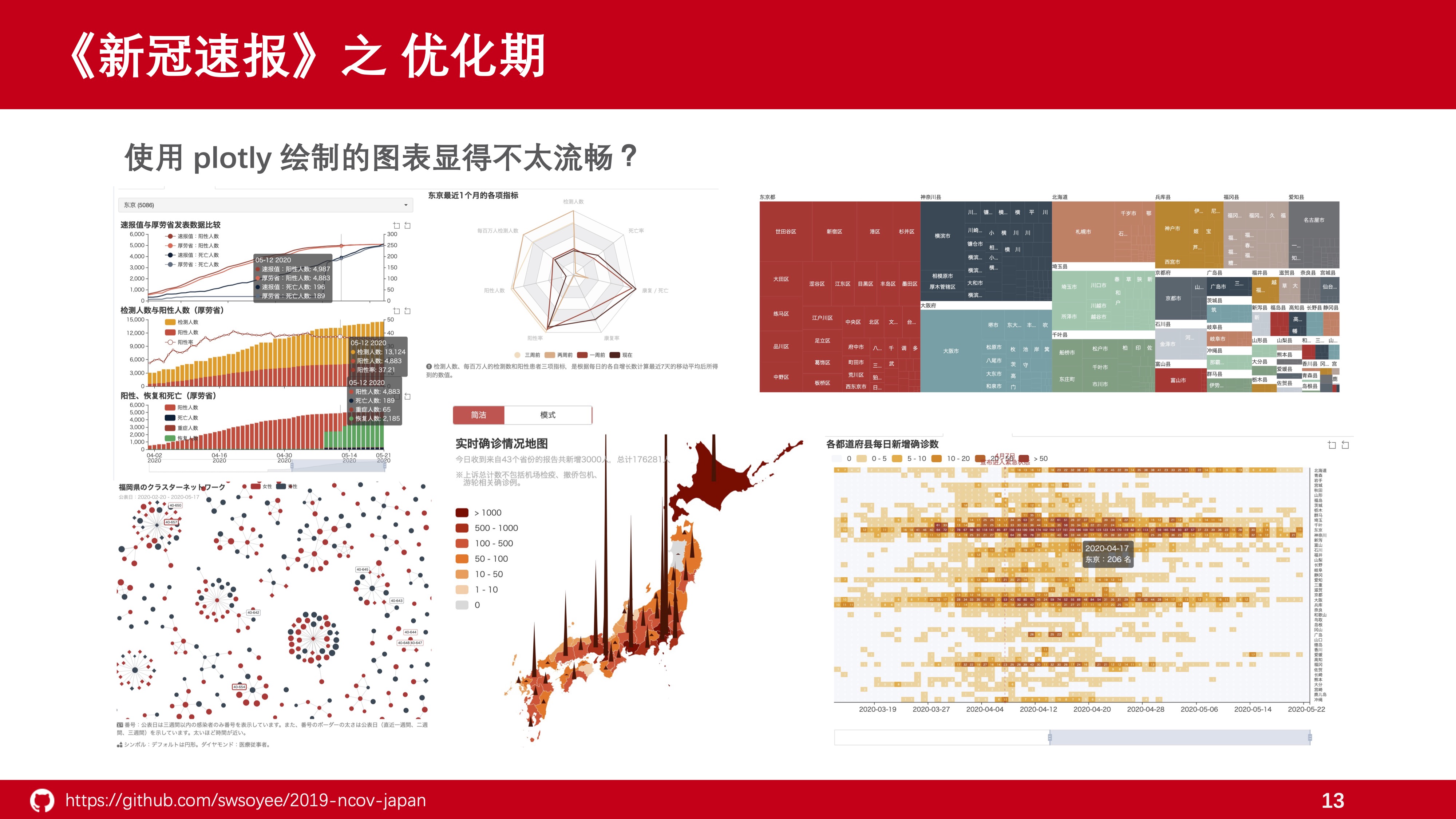
使用 Echarts4r 你可以在很短的时间内完成具有很强互动性的可视化图表,官方的配置项文档也写得非常明晰易懂,更重要的是由于是百度团队主导的项目,因此中文文档十分齐全,用起来非常顺手。 那除了 Echarts4r 外还有没有选择呢?当然有,不过这一点我们在后续讲别的时候会提到所以这里就不做讲解了。

我们的访问量在一般商业网站来看,其实这点流量根本算不上什么,但是对于私人由 {shiny} 所搭建的网站来说,由于免费版的 shiny-server 只允许单进程,因此只要同时打开网站的用户一多,结果就是发生阻塞然后大家都打不开页面的情况。
对于这一部分应该如何进行优化,我们可以使用 ShinyProxy 或者上 Kubernetes,用上负载均衡等等方法来解决,但这一部分的内容更为复杂和超纲了,所以在这里我只稍微介绍一下前端数值展示页面应该如何优化。
第一个,对于首页不太重要的图表,用户不太关注但是却不是没用的地方可以选择默认折叠不显示,从而降低首页各类图表渲染的压力。这个很容易明白就不作详细介绍了。

页面内容按需加载其实也不用太多说,比方说有很多初学者习惯一次性把所需要的数据在应用启动之初,把他们作为全局变量保存起来使用,这自然大大延长了应用的首屏时间,也就是用户打开页面到第一屏渲染完成的时间。
其实我们在页面上的每一个可点击元素的动作都可以在 {shiny} 这边进行监测到,所以只要用户触发了某个按键后再进行数据集加载即可。
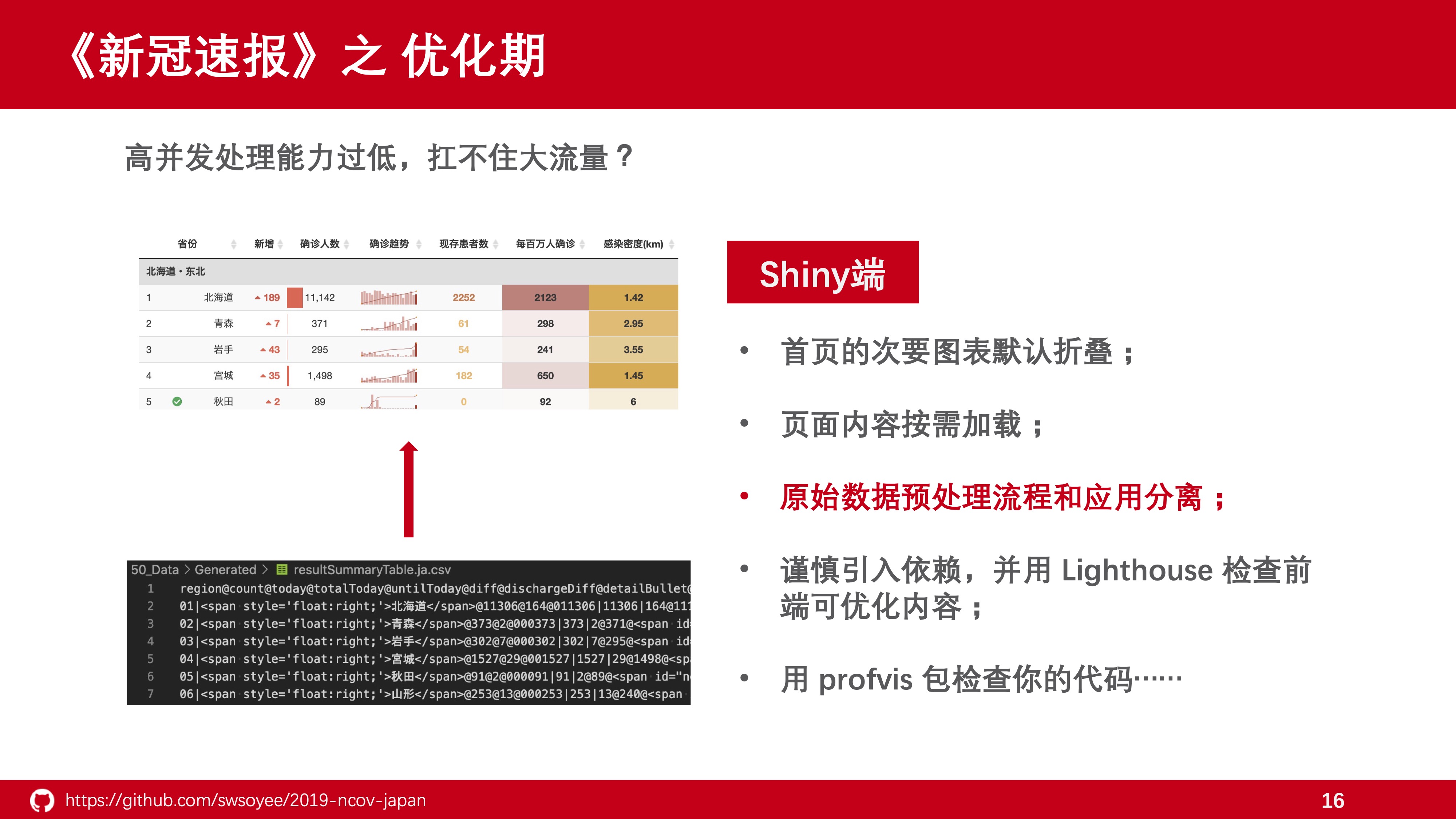
第三点,原始数据先在本地处理完成后在配置到应用中去。这点其实也不难想到,但对于初学者来说也是挺容易忽略的一点。
举个例子,之前也提到《新冠速报》首页展示各都道府县情况的表格为了提供尽可能多的信息量,在表格中插入了大量的 html 标签,包括迷你图和各类颜色,特别是在生成迷你图部分需要较多的数据变换操作,可能在本地展示的时候,整体渲染速度还行,一旦上线,只要多几个用户访问,马上就拉胯了。
所以这部分运算完全可以剖离在应用外,在持续集成阶段生成展示需要的表格,这样将会大大降低服务器的运行压力。简单来说大概就是从 1 分钟到七八秒的差别吧。

当我们刚开始学会了如何在 {shiny} 中添加很多酷炫的东西的时候,很容易不管实际用户体验如何,为了酷炫就使劲往加载各种各样的包。
其实这么做只会让你的应用越来越慢,如果你用的是 shinyapps.io 的免费托管的话,就算做得再怎么优秀,那就好想断网一样的启动速度,我估计用户留存率也低得可怕的。所以在酷炫的同时,可以使用谷歌浏览器的 Lighthouse 这个免费工具来对你的应用进行优化,比如一些根本没用到的 JavaScript 依赖或 css 样式文件能删掉就删掉,从而加快整个页面的渲染速度。
比方说 《新冠速报》 中没有用到任何 3d 图表,那么我们就可以下载 {echarts4r} 的源代码,把 3d 相关的 JS 代码给删除后重新打包。
这个操作比较麻烦,如果不是商用产品做这么细致其实也没太必要,但是我们仍然可以严格控制额外引入的依赖项,减法难做那就控制加法,从而优化我们的应用。

此外,很多时候我们为了快速实现某种功能,而忽视了代码的执行效率。
但如果置之不理的话,很容易在各种地方埋下隐患,从而拖累我们的应用。这个时候我们就可以定期的使用 {profvis} 这个包,检查造成我们应用效率低下的罪魁祸首,进而对部分的代码进行重构和优化,从而提升应用的整体性能。
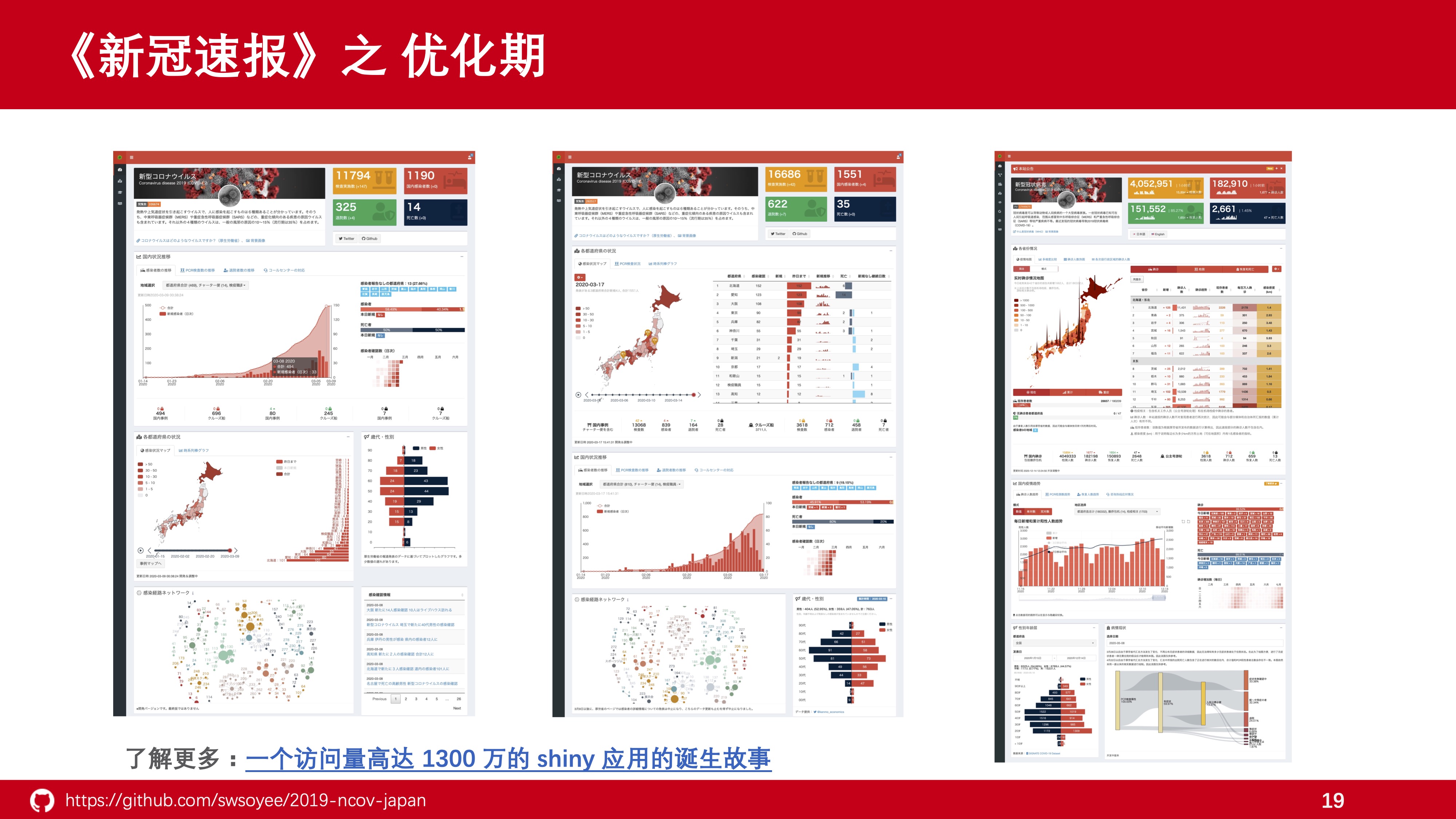
最后经过了不断的优化,才最终呈现为现在用户访问时候的界面。 其实现在这个样子还有很多需要完善和开发的地方,奈何实在是个人精力有限也只能作罢。 至于应用的具体介绍方面我在 9 月份的时候也写过一篇介绍,如果感兴趣的听众也可以去看看,在这里由于时间关系也就不详细展示了。

以上就是《新冠速报》在R能够做的范围内所采用的一些优化的方法,逐步的对产品进行升级换代,从而提升了用户体验。
最后由于时间关系,再稍微简单的聊一下,觉得要是当初做了就更好了的一些小遗憾。
第一个是,我们最好在项目启动之前,对成品有一个大致的草稿,了解我们可能会需要些什么包来实现需求。比方说在选择应用的主体外观时,除了 {shinydashboard},还有{bs4dash},{shinyMobile} 等等主题包给我们选择。
我也是在基本完成了《新冠速报》的开发后,才了解到还有bs4dash这款更新一点更酷炫点主题包,然而当我尝试迁移的时候,发现工作量非常大,最后只能放弃。
再者,如果事先调查清楚了 {echarts4r} 等更方便好用的可视化的时候 ,那我就完全不需要再花费额外的工作量在从 {plotly} 迁移到 {echart4r} 上来了。
在这里我要强烈推荐肖楠大大的,{shiny} 相关软件包汇总介绍仓库,立项的时候可以浏览筛选一下可能会用上的依赖,做好计划后再开始动手,从而减少遗憾。

最后一点就是要做好依赖的版本控制。简单的来说就是用一个文件来记录你所使用的所有包的版本号。既方便他人一键进行所有依赖的正确配置,也同时能够使得你不会因为依赖的破坏性升级导致你的应用出错。
最好的一个例子就是我在开始做这个项目的时候因为脱离R开发太久了还不知道有 {renv} 这个依赖管理器就这么开始了,结果 {echarts4r} 在前阵子的对矩形树图的参数进行了调整,假设你把新冠速报的仓库整体下到本地,全用最新版本的依赖的话,就会发现矩形树图的可视化是会报错的。如果进行了依赖版本管理的话,至少能回避这个问题了。

在报告的最后,我把这一次没有干货的分享中,主要提到的几点内容列在了这张 PPT 上了。如果能帮助到 {shiny} 初学者在开发中少踩一些坑那么就达到了我这次分享的目的了。
《新冠速报》的项目地址在页脚中也有了,如果感兴趣的话可以去 Github 下载一下,或者给项目加个星支持。
不过由于自己在开发它的时候水平比较低,甚至刚开始写它的时候连 R 包都还不会写,
所以代码的质量很低,仅供参考而不建议模仿。